在目标检测任务中,存在特殊的挑战:
(1)目标检测任务标签信息量更大,根据标签学到的模型更为复杂,压缩后损失更多
(2)分类任务中,每个类别相对均衡,同等重要,而目标检测任务中,存在类别不平衡问题,背景类偏多
(3)目标检测任务更为复杂,既有类别分类,也有位置回归的预测
(4)现行的知识蒸馏主要针对同一域中数据进行蒸馏,对于跨域目标检测的任务而言,对知识的蒸馏有更高的要求
Abstract
Despite significant accuracy improvement in convolutional neural networks (CNN) based object detectors, they often require prohibitive runtimes to process an image for real-time applications. State-of-the-art models often use very deep networks with a large number of floating point operations. Efforts such as model compression learn compact models with fewer number of parameters, but with much reduced accuracy. In this work, we propose a new framework to learn compact and fast object detection networks with improved accuracy using knowledge distillation [20] and hint learning [34]. Although knowledge distillation has demonstrated excellent improvements for simpler classification setups, the complexity of detection poses new challenges in the form of regression, region proposals and less voluminous labels. We address this through several innovations such as a weighted cross-entropy loss to address class imbalance, a teacher bounded loss to handle the regression component and adaptation layers to better learn from intermediate teacher distributions. We conduct comprehensive empirical evaluation with different distillation configurations over multiple datasets including PASCAL, KITTI, ILSVRC and MS-COCO. Our results show consistent improvement in accuracy-speed trade-offs for modern multi-class detection models.
翻译:
尽管基于卷积神经网络(CNN)的目标检测器在准确性方面取得了显著的提高,但它们往往需要禁止的运行时间来处理图像以用于实时应用。最先进的模型通常使用非常深层的网络和大量的浮点运算。诸如模型压缩之类的工作学习具有更少参数的紧凑模型,但准确性大大降低。在本工作中,我们提出了一种新的框架,使用知识蒸馏和提示学习来学习紧凑且快速的目标检测网络,并改善准确性。尽管知识蒸馏在简单分类设置中表现出了出色的改进,但检测的复杂性提出了新的挑战,例如回归、区域提议和较少数量的标签。我们通过几项创新来解决这些挑战,例如加权交叉熵损失来解决类别不平衡问题,教师边界损失来处理回归组件,并且使用适应层更好地从中间教师分布中学习。我们在多个数据集上对不同的蒸馏配置进行了全面的实证评估,包括PASCAL、KITTI、ILSVRC和MS-COCO。我们的结果显示,对于现代多类别检测模型,准确性和速度的折衷一直得到了一致的改善。
Introduction
On the other hand, seminal works on knowledge distillation show that a shallow or compressed model trained to mimic the behavior of a deeper or more complex model can recover some or all of the accuracy drop [3, 20, 34]. However, those results are shown only for problems such as classification, using simpler networks without strong regularization such as dropout.
Applying distillation techniques to multi-class object detection, in contrast to image classification, is challenging for several reasons. First, the performance of detection models suffers more degradation with compression, since detection labels are more expensive and thereby, usually less voluminous.Second, knowledge distillation is proposed for classification assuming each class is equally important, whereas that is not the case for detection where the background class is far more prevalent. Third, detection is a more complex task that combines elements of both classification and bounding box regression. Finally, an added challenge is that we focus on transferring knowledge within the same domain (images of the same dataset) with no additional data or labels, as opposed other works that might rely on data from other domains (such as high-quality and low-quality image domains, or image and depth domains)
翻译:
另一方面,关于知识蒸馏的重要研究表明,一个浅层或压缩的模型训练成模仿更深或更复杂模型的行为可以恢复部分或全部准确性下降。然而,这些结果仅适用于诸如分类等问题,使用没有像dropout这样强的正则化的简单网络。
与图像分类相比,将蒸馏技术应用于多类目标检测具有挑战性,原因有几个。首先,由于检测标签更昂贵,通常情况下数量更少,因此检测模型的性能在压缩时会更受影响。其次,知识蒸馏被提出用于分类,假设每个类别同等重要,而在检测中情况并非如此,背景类别更为普遍。第三,检测是一个更复杂的任务,结合了分类和边界框回归的元素。最后,一个额外的挑战是,我们专注于在同一领域内(同一数据集的图像)传递知识,没有额外的数据或标签,而其他工作可能依赖于来自其他领域的数据(例如高质量和低质量图像领域,或图像和深度领域)。
总结:
KD一开始的应用领域不是目标检测,目标检测比分类复杂,需要改进;没有使用伪标签
To address the above challenges, we propose a method to train fast models for object detection with knowledge distillation. Our contributions are four-fold:
• We propose an end-to-end trainable framework for learning compact multi-class object detection models through knowledge distillation (Section 3.1). To the best of our knowledge, this is the first successful demonstration of knowledge distillation for the multi-class object detection problem.
• We propose new losses that effectively address the aforementioned challenges. In particular, we propose a weighted cross entropy loss for classification that accounts for the imbalance in the impact of misclassification for background class as opposed to object classes (Section 3.2), a teacher bounded regression loss for knowledge distillation (Section 3.3) and adaptation layers for hint learning that allows the student to better learn from the distribution of neurons in intermediate layers of the teacher (Section 3.4).
• We perform comprehensive empirical evaluation using multiple large-scale public benchmarks.Our study demonstrates the positive impact of each of the above novel design choices, resulting in significant improvement in object detection accuracy using compressed fast networks, consistently across all benchmarks (Sections 4.1 – 4.3).
• We present insights into the behavior of our framework by relating it to the generalization and under-fitting problems (Section 4.4).
翻译:
为了解决上述挑战,我们提出了一种使用知识蒸馏训练快速目标检测模型的方法。我们的贡献有四个方面:
• 我们提出了一个端到端可训练的框架,通过知识蒸馏学习紧凑的多类目标检测模型(第3.1节)。据我们所知,这是对多类目标检测问题进行知识蒸馏的首次成功演示。
• 我们提出了新的损失函数,有效解决了上述挑战。特别地,我们提出了一种加权交叉熵损失,用于分类,考虑了对背景类别和目标类别的误分类影响不平衡(第3.2节),一种用于知识蒸馏的教师边界回归损失(第3.3节),以及用于提示学习的适应层,允许学生更好地从教师的中间层神经元分布中学习(第3.4节)。
• 我们使用多个大规模公共基准进行了全面的实证评估。我们的研究表明了上述每个新设计选择的积极影响,在所有基准测试中,使用压缩快速网络显著提高了目标检测准确性(第4.1 - 4.3节)。
• 我们通过将其与泛化和欠拟合问题相关联,提供了对我们框架行为的深入见解(第4.4节)。
Related Works
相较于已有的KD+目标检测,最近一个是用目标检测模型做二分类,和多分类任务还是有差别
Method
Overall Structure
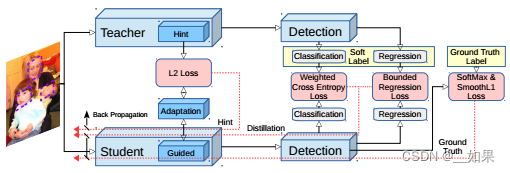
对于主干网络,作者使用FitNet中的hint learning进行蒸馏,即加入adaptation layers使得feature map的维度匹配
对于分类任务的输出,使用加权cross entropy loss来解决类别失衡严重问题
对于回归任务,除了原本的smooth L1 loss,作者还提出teacher bounded regression loss,将教师的回归预测作为上界,学生网络回归的结果更优则该损失为0。


Knowledge Distillation for Classification with Imbalanced Classes
对于分类损失中的背景误分概率占比较高的情况,作者提出增大蒸馏交叉熵中背景类的权重来解决失衡问题
令背景类的wc为1,目标类为1.5
![]()
Knowledge Distillation for Regression with Teacher Bounds
对于回归结果的蒸馏,由于回归的输出是无界的,且教师网络的预测方向可能与groundtruth的方向相反。因此,作者将教师的输出损失作为上界,当学生网络的输出损失大于上界时计入该损失否则不考虑该loss。
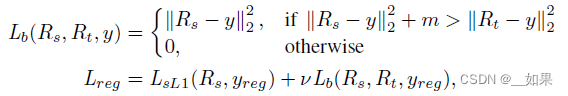
Hint Learning with Feature Adaptation
添加一个adapt层效果会更好,哪怕引导层和提示层的维度相同
FitNets中hint learning的误差
Conclusion
We propose a novel framework for learning compact and fast CNN based object detectors with the knowledge distillation. Highly complicated detector models are used as a teacher to guide the learning process of efficient student models. Combining the knowledge distillation and hint framework together with our newly proposed loss functions, we demonstrate consistent improvements over various experimental setups. Notably, the compact models trained with our learning framework execute significantly faster than the teachers with almost no accuracy compromises at PASCAL dataset. Our empirical analysis reveals the presence of under-fitting issue in object detector learning, which could provide good insights to further advancement in the field.
翻译:
我们提出了一种新颖的框架,利用知识蒸馏来学习紧凑且高效的基于CNN的目标检测器。高度复杂的检测器模型被用作教师,来引导高效的学生模型的学习过程。将知识蒸馏和提示框架与我们新提出的损失函数结合起来,我们在各种实验设置中展示了持续的改进。值得注意的是,使用我们的学习框架训练的紧凑模型在PASCAL数据集上的执行速度显著快于教师模型,几乎没有准确性的妥协。我们的实证分析揭示了目标检测学习中存在欠拟合问题的存在,这可能为该领域的进一步发展提供了有益的见解。